Summary: in this tutorial, you will learn how to find duplicate records in the Oracle Database.
Let’s start by setting up a sample table for the demonstration.
Setting up a sample table #
First, the following statement creates a new table fruits that consists of three columns: fruit id, fruit name, and color:
CREATE TABLE fruits (
fruit_id NUMBER generated BY DEFAULT AS IDENTITY,
fruit_name VARCHAR2(100),
color VARCHAR2(20)
);
Code language: SQL (Structured Query Language) (sql)Second, insert some rows into the fruits table:
INSERT INTO fruits(fruit_name,color) VALUES('Apple','Red');
INSERT INTO fruits(fruit_name,color) VALUES('Apple','Red');
INSERT INTO fruits(fruit_name,color) VALUES('Orange','Orange');
INSERT INTO fruits(fruit_name,color) VALUES('Orange','Orange');
INSERT INTO fruits(fruit_name,color) VALUES('Orange','Orange');
INSERT INTO fruits(fruit_name,color) VALUES('Banana','Yellow');
INSERT INTO fruits(fruit_name,color) VALUES('Banana','Green');
Code language: SQL (Structured Query Language) (sql)Third, query data from the fruits table:
SELECT * FROM fruits;
Code language: SQL (Structured Query Language) (sql)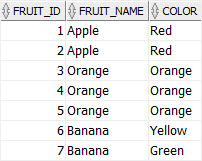
As you can see from the picture above, the fruits table has duplicate records with the same information repeated in both fruit_name and color columns.
Finding duplicate rows using the aggregate function #
To find duplicate rows from the fruits table, you first list the fruit name and color columns in both SELECT and GROUP BY clauses. Then you count the number of appearances each combination appears with the COUNT(*) function as shown below:
SELECT
fruit_name,
color,
COUNT(*)
FROM
fruits
GROUP BY
fruit_name,
color;
Code language: SQL (Structured Query Language) (sql)
The query returned a single row for each combination of fruit name and color. It also included the rows without duplicates.
To return just the duplicate rows whose COUNT(*) is greater than one, you add a HAVING clause as follows:
SELECT
fruit_name,
color,
COUNT(*)
FROM
fruits
GROUP BY
fruit_name,
color
HAVING COUNT(*) > 1;
Code language: SQL (Structured Query Language) (sql)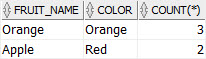
So now we have duplicated record. It shows one row for each copy.
If you want to return all the rows, you need to query the table again as shown below:
SELECT *
FROM fruits
WHERE (fruit_name, color) IN
(SELECT fruit_name,
color
FROM fruits
GROUP BY fruit_name,
color
HAVING COUNT(*) > 1
)
ORDER BY fruit_name, color;
Code language: SQL (Structured Query Language) (sql)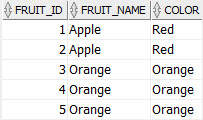
Now, we have all duplicate rows displayed in the result set.
Finding duplicate records using analytic function #
See the following query:
SELECT f.*,
COUNT(*) OVER (PARTITION BY fruit_name, color) c
FROM fruits f;
Code language: SQL (Structured Query Language) (sql)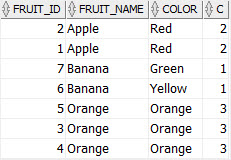
In this query, we added an OVER() clause after the COUNT(*) and placed a list of columns, which we checked for duplicate values, after a partition by clause. The partition by clause split rows into groups.
Different from using the GROUP BY above, the analytic function preserves the result set, therefore, you still can see all the rows in the table once.
Because you can use the analytic function in the WHERE or HAVING clause, you need to use the WITH clause:
WITH fruit_counts AS (
SELECT f.*,
COUNT(*) OVER (PARTITION BY fruit_name, color) c
FROM fruits f
)
SELECT *
FROM fruit_counts
WHERE c > 1 ;
Code language: SQL (Structured Query Language) (sql)Or you need to use an inline view:
SELECT
*
FROM
(SELECT f.*,
COUNT(*) OVER (PARTITION BY fruit_name, color) c
FROM fruits f
)
WHERE c > 1;
Code language: SQL (Structured Query Language) (sql)Now, you should know how to find duplicate records in Oracle Database. It’s time to clean up your data by removing the duplicate records.